Quick links
Quick News
Recent News
Description
Main features
Supported Platforms
Performance
Reliability
Security
They use it!
Enterprise Features
Third party extensions
Commercial Support
Add-on features
Other Solutions
Discussions
Slack channel
Mailing list
10GbE load-balancing
Contributions
Coding style
Open Issues
Known bugs
HATop: Ncurses Interface
Herald: load feedback agent
haproxystats: stats collection
Alpine-based Docker images
Debian-based Docker images
RHEL-based Docker images
Debian/Ubuntu packages
 visitors online visitors online


Thanks for your support !





|
|
This page is an unsorted list of old info and old links,
some of which are probably still valid but definitely
outdated. They have been removed from the main site on
2021-11-23 in order to keep it clean, and are undergoing a
manual cleanup to only keep relevant and possibly useful
stuff. It's not expected that you'd need anything from
this page.
HAProxy is a free, very fast and reliable solution offering
high availability,
load balancing, and
proxying for TCP and HTTP-based applications. It is particularly suited for very
high traffic web sites and powers quite a number of the world's most visited ones.
Over the years it has become the de-facto standard opensource load balancer, is
now shipped with most mainstream Linux distributions, and is often deployed by
default in cloud platforms. Since it does not advertise itself, we only know it's
used when the admins report it :-)
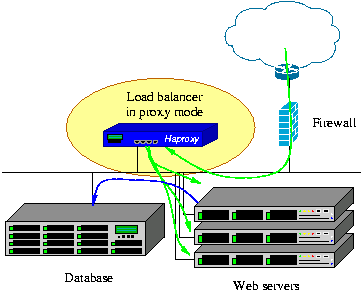
Its mode of operation makes its integration into existing architectures very easy
and riskless, while still offering the possibility not to expose fragile web servers
to the net, such as below :
We always support at least two active versions in parallel and an extra old
one in critical fixes mode only. The currently supported versions are :
- version 2.4 : syslog and DNS over TCP, multi-threaded Lua, full sharing of idle conns, lower latency, server-side dynamic SSL update, Opentracing, WebSocket over H2, atomic maps, Vary support, new debugging tools, even more user-friendly CLI and configuration, lots of cleanups
- version 2.3 : syslog forwarding, better idle conn management, improved balancing with large queues, simplified SSL managment, more stats metrics, stricter config checking by default, general performance improvements
- version 2.2 : runtime certificate additions, improved idle connection management, logging over TCP, HTTP "return" directive, errorfile templates, TLSv1.2 by default, extensible health-checks
- version 2.1 : improved I/Os and multi-threading, FastCGI, runtime certificate updates, HTX-only, improved debugging, removal of obsolete keywords
- version 2.0 : gRPC, layer 7 retries, process manager, SSL peers, log load balancing/sampling, end-to-end TCP fast-open, automatic settings (maxconn, threads, HTTP reuse, pools), ...
- version 1.9 : improved multi-threading, end-to-end HTTP/2, connection pools, queue priority control, stdout logging, ...
- version 1.8 : multi-threading, HTTP/2, cache, on-the fly server addition/removal, seamless reloads, DNS SRV, hardware SSL engines, ...
- version 1.7 : added server hot reconfiguration, content processing agents, multi-type certs, ...
- version 1.6 : added DNS resolution support, HTTP connection multiplexing, full stick-table replication, stateless compression, ...
- version 1.5 : added SSL, IPv6, keep-alive, DDoS protection, ...
Each version brought its set of features on top of the previous one.
Upwards compatibility is a very important aspect of HAProxy, and even
version 1.5 is able to run with configurations made for version 1.0 13
years before. Version 1.6 dropped a few long-deprecated keywords and
suggests alternatives. The most differenciating features of each version
are listed below :
- version 1.5, released in 2014
This version further expands 1.4 with 4 years of hard work :
native SSL support on both sides with SNI/NPN/ALPN and OCSP stapling,
IPv6 and UNIX sockets are supported everywhere,
full HTTP keep-alive for better support of NTLM and improved efficiency in static farms,
HTTP/1.1 compression (deflate, gzip) to save bandwidth,
PROXY protocol versions 1 and 2 on both sides,
data sampling on everything in request or response, including payload,
ACLs can use any matching method with any input sample
maps and dynamic ACLs updatable from the CLI
stick-tables support counters to track activity on any input sample
custom format for logs, unique-id, header rewriting, and redirects,
improved health checks (SSL, scripted TCP, check agent, ...),
much more scalable configuration supports hundreds of thousands of backends and certificates without sweating
- version 1.4, released in 2010
This version has brought its share of new features over 1.3, most of which were long awaited :
client-side keep-alive to reduce the time to load heavy pages for clients over the net,
TCP speedups to help the TCP stack save a few packets per connection,
response buffering for an even lower number of concurrent connections on the servers,
RDP protocol support with server stickiness and user filtering,
source-based stickiness to attach a source address to a server,
a much better stats interface reporting tons of useful information,
more verbose health checks reporting precise statuses and responses in stats and logs,
traffic-based health to fast-fail a server above a certain error threshold,
support for HTTP authentication for any request including stats, with support for password encryption,
server management from the CLI to enable/disable and change a server's weight without restarting haproxy,
ACL-based persistence to maintain or disable persistence based on ACLs, regardless of the server's state,
log analyzer to generate fast reports from logs parsed at 1 Gbyte/s,
- version 1.3, released in 2006
This version has brought a lot of new features and improvements over 1.2, among which
content switching to select a server pool based on any request criteria,
ACL to write content switching rules, wider choice of
load-balancing algorithms for better integration,
content inspection allowing to block unexpected protocols,
transparent proxy under Linux, which allows to directly connect to
the server using the client's IP address, kernel TCP splicing to forward
data between the two sides without copy in order to reach multi-gigabit data rates,
layered design separating sockets, TCP and HTTP processing for more
robust and faster processing and easier evolutions, fast and fair scheduler
allowing better QoS by assigning priorities to some tasks, session rate limiting
for colocated environments, etc...
Version 1.2 has been in production use since 2006 and provided an improved performance level
on top of 1.1. It is not maintained anymore, as most of its users have switched to 1.3 a long
time ago. Version 1.1, which has been maintaining critical sites online since 2002, is not
maintained anymore either. Users should upgrade to 1.4 or 1.5.
HAProxy is known to reliably run on the following OS/Platforms :
- Linux 2.4 on x86, x86_64, Alpha, Sparc, MIPS, PARISC
- Linux 2.6-5.x on x86, x86_64, ARM, AARCH64, MIPS, Sparc, PPC64
- Solaris 8/9 on UltraSPARC 2 and 3
- Solaris 10 on Opteron and UltraSPARC
- FreeBSD 4.10 - current on x86
- OpenBSD 3.1 to -current on i386, amd64, macppc, alpha, sparc64 and VAX (check the ports)
- AIX 5.1 - 5.3 on Power™ architecture
Highest performance is achieved with modern operating systems supporting scalable polling mechanisms such as
epoll on Linux 2.6/3.x or kqueue
on FreeBSD and OpenBSD. This requires haproxy version newer than 1.2.5. Fast data transfers are made possible
on Linux 3.x using TCP splicing and haproxy 1.4 or 1.5. Forwarding rates of up to 40 Gbps have already been
achieved on such platforms after a very careful tuning. While Solaris and AIX are supported, they should not
be used if extreme performance is required.
Current typical 1U servers equipped with an hex- to octa- core processor typically achieve
between 200000 and 500000 requests/s and have no trouble saturating 25 Gbps ethernet under Linux.
[ warning: information in this section dates 2007, things have improved by an order of magnitude since then ]
[ for a more up to date report of what is possible in 2021, see this test run on AWS ARM-based Graviton2 reaching 2 million requests/s and 100 Gbps ]
Well, since a user's testimony is better than a long demonstration, please take a look at
Chris Knight's experience
with haproxy saturating a gigabit fiber in 2007 on a video download site. Since then,
the performance has significantly increased and the hardware has become much more capable, as
my experiments with
Myricom's 10-Gig NICs have shown two years later. Now as of
2014, 10-Gig NICs are too limited and are hardly suited for 1U servers since they do rarely
provide enough port density to reach speeds above 40-60 Gbps in a 1U server. 100-Gig NICs
are coming and I expect to run new series of tests when they are available.
HAProxy involves several techniques commonly found in Operating Systems
architectures to achieve the absolute maximal performance :
- a single-process,
event-driven model considerably reduces the cost of
context switch
and the memory usage. Processing several hundreds of tasks in a millisecond is
possible, and the memory usage is in the order of a few kilobytes per session
while memory consumed in preforked or threaded servers is more in the order of
megabytes per process.
- O(1) event checker on systems that allow it (Linux and FreeBSD)
allowing instantaneous detection of any event on any connection among tens of
thousands.
- Delayed updates to the event checker using a lazy event cache ensures
that we never update an event unless absolutely required. This saves a lot of
system calls.
- Single-buffering without any data copy between reads and writes whenever
possible. This saves a lot of CPU cycles and useful memory bandwidth. Often,
the bottleneck will be the I/O busses between the CPU and the network
interfaces. At 10-100 Gbps, the memory bandwidth can become a bottleneck too.
- Zero-copy forwarding is possible using the splice() system
call under Linux, and results in real zero-copy starting with Linux 3.5. This
allows a small sub-3 Watt device such as a Seagate Dockstar to forward HTTP
traffic at one gigabit/s.
- MRU
memory allocator using fixed size memory pools for immediate memory
allocation favoring hot cache regions over cold cache ones. This dramatically
reduces the time needed to create a new session.
- Work factoring, such as multiple accept() at once, and
the ability to limit the number of accept() per iteration when
running in multi-process mode, so that the load is evenly distributed among
processes.
- CPU-affinity is supported when running in multi-process mode, or simply
to adapt to the hardware and be the closest possible to the CPU core managing the
NICs while not conflicting with it.
- Tree-based storage, making heavy use of the Elastic Binary tree I have
been developping for several years. This is used to keep timers ordered, to keep
the runqueue ordered, to manage round-robin and least-conn queues, to look up ACLs
or keys in tables, with only an O(log(N)) cost.
- Optimized timer queue : timers are not moved in the tree if they are
postponed, because the likeliness that they are met is close to zero since they're
mostly used for timeout handling. This further optimizes the ebtree usage.
- optimized HTTP header analysis : headers are parsed an interpreted on
the fly, and the parsing is optimized to avoid an re-reading of any previously
read memory area. Checkpointing is used when an end of buffer is reached with
an incomplete header, so that the parsing does not start again from the
beginning when more data is read. Parsing an average HTTP request typically
takes half a microsecond on a fast Xeon E5.
- careful reduction of the number of expensive system calls. Most of the
work is done in user-space by default, such as time reading, buffer aggregation,
file-descriptor enabling/disabling.
- Content analysis is optimized to carry only pointers to original data and
never copy unless the data needs to be transformed. This ensures that very
small structures are carried over and that contents are never replicated when
not absolutely necessary.
All these micro-optimizations result in very low CPU usage even on moderate
loads. And even at very high loads, when the CPU is saturated, it is quite common
to note figures like 5% user and 95% system, which means that the
HAProxy process consumes about 20 times less than its system counterpart. This
explains why the tuning of the Operating System is very important. This
is the reason why we ended up building
our own appliances,
in order to save that complex and critical task from the end-user.
In production, HAProxy has been installed several times as an emergency solution
when very expensive, high-end hardware load balancers suddenly failed on Layer 7
processing. Some hardware load balancers still do not use proxies and process requests
at the packet level and have a great difficulty at supporting
requests across multiple packets and high response
times because they do no buffering at all. On the
other side, software load balancers use TCP buffering
and are insensible to long requests and high response times. A
nice side effect of HTTP buffering is that it
increases the server's connection acceptance by reducing the
session duration, which leaves room for new requests.
There are 3 important factors used to measure a load balancer's performance :
- The session rate
This factor is very important, because it directly determines when the load
balancer will not be able to distribute all the requests it receives. It is
mostly dependant on the CPU.
Sometimes, you will hear about requests/s or hits/s, and they are the same as
sessions/s in HTTP/1.0 or HTTP/1.1 with
keep-alive disabled. Requests/s with keep-alive enabled is generally much
higher (since it significantly reduces system-side work) but is often meaningless
for internet-facing deployments since clients often open a large amount of connections
and do not send many requests per connection on avertage. This factor is
measured with varying object sizes, the fastest results generally coming from
empty objects (eg: HTTP 302, 304 or 404 response codes).
Session rates around 100,000 sessions/s can be achieved on Xeon E5
systems in 2014.
- The session concurrency
This factor is tied to the previous one. Generally, the session rate
will drop when the number of concurrent sessions increases (except with the
epoll or kqueue polling mechanisms). The slower
the servers, the higher the number of concurrent sessions for a same session rate.
If a load balancer receives 10000 sessions per second and the servers respond in
100 ms, then the load balancer will have 1000 concurrent sessions. This number is
limited by the amount of memory and the amount of file-descriptors the system can
handle. With 16 kB buffers, HAProxy will need about 34 kB per session, which
results in around 30000 sessions per GB of RAM. In practise, socket
buffers in the system also need some memory and 20000 sessions per GB of RAM is
more reasonable. Layer 4 load balancers generally announce millions of
simultaneous sessions because they need to deal with the TIME_WAIT sockets
that the system handles for free in a proxy. Also they don't process any data
so they don't need any buffer. Moreover, they are sometimes designed to be used
in Direct Server Return mode, in which the load balancer only sees forward
traffic, and which forces it to keep the sessions for a long time after their end
to avoid cutting sessions before they are closed.
- The data forwarding rate
This factor generally is at the opposite of the session rate. It is measured
in Megabytes/s (MB/s), or sometimes in Gigabits/s (Gbps). Highest data rates
are achieved with large objects to minimise the overhead caused by session
setup and teardown. Large objects generally increase session concurrency, and
high session concurrency with high data rate requires large amounts of memory
to support large windows. High data rates burn a lot of CPU and bus cycles on
software load balancers because the data has to be copied from the input
interface to memory and then back to the output device. Hardware load balancers
tend to directly switch packets from input port to output port for higher data
rate, but cannot process them and sometimes fail to touch a header or a cookie.
Haproxy on a typical Xeon E5 of 2014 can forward data up to about 40 Gbps.
A fanless 1.6 GHz Atom CPU is slightly above 1 Gbps.
A load balancer's performance related to these factors is generally announced for
the best case (eg: empty objects for session rate, large objects for data rate).
This is not because of lack of honnesty from the vendors, but because it is not
possible to tell exactly how it will behave in every combination. So when those 3
limits are known, the customer should be aware that it will generally perform below
all of them. A good rule of thumb on software load balancers is to consider an
average practical performance of half of maximal session and data rates for
average sized objects.
You might be interested in checking the 10-Gigabit/s page.
Being obsessed with reliability, I tried to do my best to ensure a total
continuity of service by design. It's more difficult to design something
reliable from the ground up in the short term, but in the long term it reveals
easier to maintain than broken code which tries to hide its own bugs behind
respawning processes and tricks like this.
In single-process programs, you have no right to fail : the smallest bug
will either crash your program, make it spin like mad or freeze. There has not
been any such bug found in stable versions for the last 13 years, though
it happened a few times with development code running in production.
HAProxy has been installed on Linux 2.4 systems serving millions of pages
every day,
and which have only known one reboot in 3 years for a complete OS upgrade.
Obviously, they were not directly exposed to the Internet because they did not receive
any patch at all. The kernel was a heavily patched 2.4 with Robert Love's
jiffies64 patches to support time wrap-around at 497 days (which
happened twice). On such systems, the software cannot fail without being
immediately noticed !
Right now, it's being used in many Fortune 500 companies around the world to
reliably serve billions of pages per day or relay huge amounts of money. Some
people even trust it so much that they use it as the default solution to solve
simple problems (and I often tell them that they do it the dirty way). Such
people sometimes still use versions 1.1 or 1.2 which sees very limited evolutions
and which targets mission-critical usages. HAProxy is really suited for such environments
because the indicators it returns provide a lot of valuable information about the application's
health, behaviour and defects, which are used to make it even more reliable.
Version 1.3 has now received far more testing than 1.1 and 1.2 combined, so
users are strongly encouraged to migrate to a stable 1.3 or 1.4 for mission-critical
usages.
As previously explained, most of the work is executed by the Operating System.
For this reason, a large part of the reliability involves the OS itself. Latest
versions of Linux 2.4 have been known for offering the highest level of stability
ever. However, it requires a bunch of patches to achieve a high level of performance,
and this kernel is really outdated now so running it on recent hardware will often
be difficult (though some people still do). Linux 2.6 and 3.x include the features
needed to achieve this level of performance, but old LTS versions only should be
considered for really stable operations without upgrading more than once a year.
Some people prefer to run it on Solaris (or do not have the choice). Solaris 8 and
9 are known to be really stable right now, offering a level of performance comparable
to legacy Linux 2.4 (without the epoll patch). Solaris 10 might show performances
closer to early Linux 2.6. FreeBSD shows good performance but pf (the firewall)
eats half of it and needs to be disabled to come close to Linux. OpenBSD sometimes
shows socket allocation failures due to sockets staying in FIN_WAIT2 state
when client suddenly disappears. Also, I've noticed that hot reconfiguration does
not work under OpenBSD.
The reliability can significantly decrease when the system is pushed to its
limits. This is why finely tuning the sysctls is important. There is no
general rule, every system and every application will be specific. However, it is
important to ensure that the system will never run out of memory and
that it will never swap. A correctly tuned system must be able to run for
years at full load without slowing down nor crashing.
Security is an important concern when deploying a software load balancer. It is
possible to harden the OS, to limit the number of open ports and accessible
services, but the load balancer itself stays exposed. For this reason, I have been
very careful about programming style. Vulnerabilities are very rarely encountered
on haproxy, and its architecture significantly limits their impact and often allows
easy workarounds. Its remotely unpredictable even processing makes it very hard to
reliably exploit any bug, and if the process ever crashes, the bug is discovered.
All of them were discovered by reverse-analysis of an accidental crash BTW.
Anyway, much care is taken when writing code to manipulate headers. Impossible
state combinations are checked and returned, and errors are processed from the
creation to the death of a session. A few people around the world have reviewed
the code and suggested cleanups for better clarity to ease auditing. By the way,
I'm used to refuse patches that introduce suspect processing or in which not
enough care is taken for abnormal conditions.
I generally suggest starting HAProxy as root because it
can then jail itself in a chroot and drop all of its privileges
before starting the instances. This is not possible if it is not started as
root because only root can execute chroot(),
contrary to what some admins believe.
Logs provide a lot of information to help maintain a satisfying security
level. They are commonly sent over UDP because once chrooted, the
/dev/log UNIX socket is unreachable, and it must not be possible to
write to a file. The following information are particularly useful :
- source IP and port of requestor make it possible to find their origin
in firewall logs ;
- session set up date generally matches firewall logs, while tear
down date often matches proxies dates ;
- proper request encoding ensures the requestor cannot hide
non-printable characters, nor fool a terminal.
- arbitrary request and response header and cookie capture help to
detect scan attacks, proxies and infected hosts.
- timers help to differentiate hand-typed requests from browsers's.
HAProxy also provides regex-based header control. Parts of the request, as
well as request and response headers can be denied, allowed, removed, rewritten, or
added. This is commonly used to block dangerous requests or encodings (eg: the
Apache Chunk exploit),
and to prevent accidental information leak from the server to the client.
Other features such as Cache-control checking ensure that no sensible
information gets accidentely cached by an upstream proxy consecutively to a bug in
the application server for example.
If you think you don't have the time and skills to setup and maintain a free load
balancer, or if you're seeking for commercial support to satisfy your customers or
your boss, you have the following options :
- contact HAProxy Technologies
to hire some professional services or subscribe a support contract ;
- install HAProxy Enterprise Edition (HAPEE),
which is a long-term maintained HAProxy package accompanied by a well-polished collection of software, scripts,
configuration files and documentation which significantly simplifies the setup and maintenance of a completely
operational solution ; it is particularly suited to Cloud environments where deployments must be fast.
- try an ALOHA appliance
(hardware or virtual), which will even save you from having to worry about the system, hardware and from managing a Unix-like
system.
I also find it important to credit Loadbalancer.org. I am
not affiliated with them at all but like us, they have contributed a fair amount of time and money to the
project to add new features and they help users on the mailing list, so I have some respect for what they
do. They're a UK-based company and their load balancer also employs HAProxy, though it is somewhat different
from the ALOHA.
Some happy users have contributed code which may or may not be included. Others
spent a long time analysing the code, and there are some who maintain ports up to
date. The most difficult internal changes have been contributed in the form of
paid time by some big customers who can afford to pay a developer for several
months working on an opensource project. Unfortunately some of them do not want
to be listed, which is the case for the largest of them.
Some contributions were developped and not merged, most often by lack of sign of
interest from the users or simply because they overlap with some pending changes
in a way that could make it harder to maintain future compatibility.
- Geolocation support
Quite some time ago now, Cyril Bonté contacted me about a very interesting
feature he has developped, initially for 1.4, and which now supports both 1.4
and 1.5. This feature is Geolocation, which many users have been asking for
for a long time, and this one does not require to split the IP files by country
codes. In fact it's extremely easy and convenient to configure.
The feature was not merged yet because it does for a specific purpose (GeoIP)
what we wanted to have for a more general use (map converters, session variables,
and use of variables in the redirect URLs), which will allow the same features to
be implemented with more flexibility (eg: extract the IP from a header, or pass
the country code and/or AS number to a backend server, etc...). Cyril was very
receptive to these arguments and accepted to maintain his patchset out of tree
waiting for the features to be implemented (Update: 1.5-dev20 with
maps now make this possible). Cyril's code is well maintained and used in
production so there is no risk in using it on 1.4, except the fact that the
configuration statements will change a bit once you upgrade to 1.5.
The code and documentation are available here : https://github.com/cbonte/haproxy-patches/wiki/Geolocation
- sFlow support
Neil Mckee posted a patch to the list in early 2013, and unfortunately this patch
did not receive any sign of interest nor feedback, which is sad considering the
amount of work that was done. I personally am clueless about sFlow and expressed
my skepticism to Neil about the benefits of sampling some HTTP traffic when you
can get much more detailed informations for free with existing logs.
Neil kindly responded with the following elements :
I agree that the logging you already have in haproxy is more flexible and detailed,
and I acknowledge that the benefit of exporting sFlow-HTTP records is not immediately
obvious.
The value that sFlow brings is that the measurements are standard, and are designed to
integrate seamlessly with sFlow feeds from switches, routers, servers and applications to
provide a comprehensive end to end picture of the performance of large scale multi-tier
systems. So the purpose is not so much to troubleshoot haproxy in isolation, but to
analyze the performance of the whole system that haproxy is part of.
Perhaps the best illustration of this is the 1-in-N sampling feature.
If you configure sampling.http to be, say, 1-in-400 then you might
only see a handful of sFlow records per second from an haproxy
instance, but that is enough to tell you a great deal about what is
going on -- in real time. And the data will not bury you even if you
have a bank of load-balancers, hundreds of web-servers, a huge
memcache-cluster and a fast network interconnect all contributing
their own sFlow feeds to the same analyzer.
Even after that explanation, no discussion emerged on the subject on the list, so
I guess there is little interest among users for now. I suspect that sFlow is
probably more deployed among network equipments than application layer equipments,
which could explain this situation. The code is large (not huge though) and I am not
convinced about the benefits of merging it and maintaining it if nobody shows even
a little bit of interest. Thus for now I prefer to leave it out of tree. Neil has
posted it on GitHub here :
https://github.com/sflow/haproxy.
Please, if you do use this patch, report your feedback to the mailing list, and invest
some time helping with the code review and testing.
This table enumerates all known significant contributions that
led to version 1.4, as well as proposed fundings and features yet to be developped but
waiting for spare time. It is not more up to date though.
Some older code contributions which possibly do not appear in the table above are still listed here.
- Application Cookies
Aleksandar Lazic and Klaus Wagner implemented this feature which
was merged in 1.2. It allows the proxy to learn cookies sent by the server
to the client, and to find it back in the URL to direct the client to the right
server. The learned cookies are automatically purged after some inactive time.
- Least Connections load balancing algorithm
This patch for haproxy-1.2.14 was submitted by Oleksandr Krailo. It implements
a basic least connection algorithm. I've not merged this version into 1.3 because
of scalability concerns, but I'm leaving it here for people who are tempted to
include it into version 1.2, and the patch is really clean.
- Soft Server-Stop
Aleksandar Lazic sent me this patch against 1.1.28 which in fact does two things.
The first interesting part allows one to write a file enumerating servers which
will have to be stopped, and then sending a signal to the running proxy to tell
it to re-read the file and stop using these servers. This will not be merged into
mainline because it has indirect implications on security since the running
process will have to access a file on the file-system, while current version can
run in a chrooted, empty, read-only directory. What is really needed is a way to
send commands to the running process. However, I understand that some people
might need this feature, so it is provided here. The second part of the patch has
been merged. It allowed both an active and a backup server to share a same
cookie. This may sound obvious but it was not possible earlier.
Usage: Aleks says that you just have to write the server names that you
want to stop in the file, then kill -USR2 the running process. I have
not tested it though.
- Server Weight
Sébastien Brize sent me this patch against 1.1.27 which adds the
'weight' option to a server to provide smoother balancing between fast and slow
servers. It is available here because there may be other people looking for this
feature in version 1.1.
I did not include this change because it has a side effect that with
high or unequal weights, some servers might receive lots of consecutive
requests. A different concept to provide a smooth and fair
balancing has been implemented in 1.2.12, which also supports
weighted hash load balancing.
Usage: specify "weight X" on a server line.
Note: configurations written with this patch applied will normally still
work with future 1.2 versions.
- IPv6 support for 1.1.27
I implemented IPv6 support on client side for 1.1.27, and merged it into
haproxy-1.2. Anyway, the patch is still provided here for people who want to
experiment with IPv6 on HAProxy-1.1.
- Other patches
Please browse the directory for other useful
contributions.
If you don't need all of HAProxy's features and are looking for a simpler solution,
you may find what you need here :
-
Linux Virtual Servers (LVS)
Very fast layer 3/4 load balancing merged in Linux 2.4 and 2.6 kernels. Should
be coupled with Keepalived to monitor
servers. This generally is the solution embedded by default in most
IP-based load balancers.
-
Nginx ("engine X")
Nginx is an excellent piece of software. Initially it's a very fast and reliable
web server, but it has grown into a full-featured proxy which can also offer
load-balancing capabilities. Nginx's load balancing features are less advanced
than haproxy's but it can do extra things (eg: caching, running FCGI apps), which
explains why they are very commonly found together. I strongly recommend it to
whoever needs a fast, reliable and flexible web server !
-
Pound
Pound is very small and reasonably good. It aims at remaining small and auditable
prior to being fast. It used to support SSL and keep-alive before HAProxy. Its
configuration file is small and simple. It's thread-based, but can be a simpler
alternative to HAProxy for a small site when the flexibility and performance of
HAProxy are not required.
-
Pen
Pen is a very simple load balancer for TCP protocols. It supports source IP-based
persistence for up to 2048 clients. Supports IP-based ACLs. Uses select()
and supports higher loads than Pound but will not scale very well to thousands of
simultaneous connections. It's more versatile however, and could be considered as
the missing link between HAProxy and socat.
|
|
